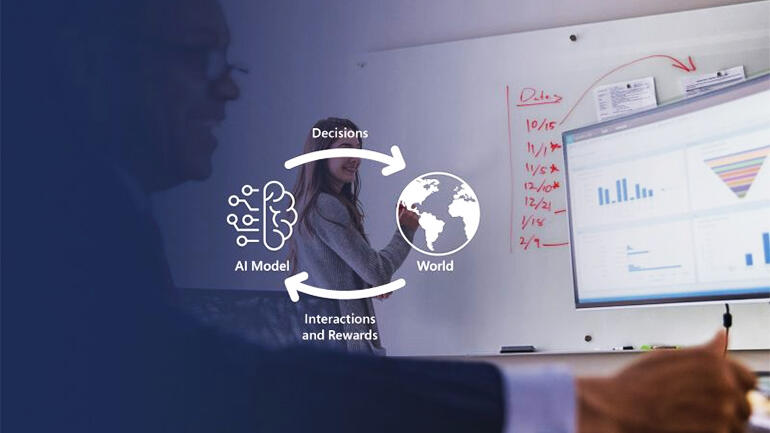
Machine learning that can explore the world can solve different problems. These are the Microsoft services that make it something mainstream developers can use.
Image: Microsoft
Humans learn by trial and error and by interacting with the environment, as well as by being taught. Parents will tell children not to push things off the table, for example — but when they do it anyway, they’ll learn that those things fall, and get an intuitive understanding of the physics behind it. Supervised machine-learning (ML) systems learn the patterns in the training data they’re given — like predicting what people might prefer based on what’s been chosen in the past — but they’re passive observers. They don’t start experimenting to see what might change those patterns, or look for additional data to better understand the problem.
Those traditional ML systems often can’t adapt when patterns change unless they’re specifically retrained. If adverts for holiday destinations used to get a lot of clicks in the middle of winter when people are longing to go somewhere warm and sunny, they’re still going to get shown even in pandemic lockdown, when those ads could look tasteless and be counterproductive.
Langford: “You can solve problems you couldn’t previously solve.”” data-credit=”Image: MIcrosoft Research” rel=”noopener noreferrer nofollow”>
Langford: “You can solve problems you couldn’t previously solve.”
Image: MIcrosoft Research
Reinforcement Learning (RL) systems are different. They learn by doing — exploring their world by making decisions that get positive or negative feedback (the rewards ‘reinforce’ the lesson being learned) for the outcomes they achieve. If the world or the outcomes change, the model learns and adapts to changing circumstances.
“Reinforcement Learning is learning on its own data,” John Langford, partner researcher manager in the RL team inside Microsoft Research, told TechRepublic.
“It’s about getting the data you’re going to learn on. You create data sets, you learn on those data sets, you deploy whatever you learn. There’s a cycle, instead of just a one-way process: that means there are additional complexities which you need to deal with, but there’s also additional opportunities. You can solve problems you couldn’t previously solve.”
The data needed to train an RL system can also be smaller than for a traditional supervised learning system by using the current context, which speeds the system up. That hasn’t always been true, according to Microsoft, as RL previously needed a lot of data.
Making little decisions
In Reinforcement Learning (RL), agents take actions based on the state of the environment and rewards for previous actions.” data-credit=”Image: Wikipedia” rel=”noopener noreferrer nofollow”>
In Reinforcement Learning (RL), agents take actions based on the state of the environment and rewards for previous actions.
Image: Wikipedia
Reinforcement Learning is good for solving what Langford calls ‘micro decisions’ in repeatable situations where the system can act by changing something — whether that’s what’s shown on-screen, the size of a buffer for a video stream, or the speed at which a screw turns to extrude cornmeal batter into an industrial fryer — and learning from what happens.
At heart, RL is the study of how AI can make decisions, Langford said. “If you can find relatively immediate feedback and there’s a decision that’s repeated many times, that’s a logical structure that comes into play in many, many places, and every time you see that, maybe you can make it work with Reinforcement Learning.”
It’s been used for teaching computers to play games — from Go to Minecraft — because games have rewards built in. But in the last couple of years, the techniques have been emerging from the research labs and into production, not just as one-off applications but as Azure Cognitive Services APIs, as tools for building autonomous systems like robots and drones and as models data scientists can use in Azure Machine Learning.
The Personalizer service is based in part on work that Langford’s team did with MSN and Bing to personalize the news you see. That resulted in improved clickthrough on MSN and a 19-fold boost in engagement with products on the Microsoft home page. Personalizer also drives the offers, product and content you see on Xbox and in the Edge browser. Any website can call the API and offer personalised content. In Mexico, Anheuser-Busch InBev personalises the products it recommends to small grocery stores in Mexico who buy from its MiMercado online marketplace; twice as many customers click on the suggestions, and the number of those clicks that turn into purchases is up 67%.
Personalizer trains a model based on data sent to it with Rank and Reward calls. The Rank API either exploits the current model to decide the best action, or explores a different action. The Reward API collects data to train and update the model.” data-credit=”Image: Microsoft” rel=”noopener noreferrer nofollow”>
Personalizer trains a model based on data sent to it with Rank and Reward calls. The Rank API either exploits the current model to decide the best action, or explores a different action. The Reward API collects data to train and update the model.
Image: Microsoft
Reinforcement Learning can improve a lot of other micro decisions, Langford says, like systems resource allocation. “Do you allocate this VM or do you hold off and keep a buffer in case something really important comes along? How many front-end web servers should you use given the way the traffic is and the traffic pattern in the recent past?” The Azure team is looking at whether RL can improve decisions about whether to try a fix a VM that’s having problems or just reboot it. And in Teams, it was used to tune the jitter buffer (which stores packets that are delivered out of order and need to be rearranged) — the right size of buffer makes for smoother video calls without noticeable delay or lag.
Reinforcement Learning could also nudge people into healthier behaviour (as well as trying a new game), by determining what question a chatbot should ask next or what messages to show them, Langford says. “Maybe people don’t have healthy habits by default, and you’d like to encourage them to walk more often. So the question is, what is the best kind of encouragement? Is it ‘yesterday you walked more’, or is it something like ‘it would be good to walk more because you promised yourself you would’? People can respond in different ways to different messages and there’s a lot of empirical evidence and studies suggesting a Reinforcement Learning approach to choosing the right advice can make a big difference in how much people actually do walk more, and how quickly they develop good habits.”
That might be because RL algorithms explore alternatives, which stops the system from being boring because it always says the same thing. But Langford notes that it’s also personalised in a way that usually doesn’t scale. “You’re getting information about what actually works best for that individual person. It would be extremely difficult to imagine judging that in advance. I don’t even know what works best for me — I have to try it for a while and see what works.”
Several teams inside Microsoft are looking at how nudging could be useful, Langford says, while the eLearning team is looking at how personalisation could be useful. “The Personalizer service has a pretty general interface,” he explains. “You send in features, you get back a decision and then you send back a reward.”
Anomaly Detector uses RL to detect spikes, dips and other time-series events, such as trend change and off-cycle softness.” data-credit=”Image: Microsoft” rel=”noopener noreferrer nofollow”>
Anomaly Detector uses RL to detect spikes, dips and other time-series events, such as trend change and off-cycle softness.
Image: Microsoft
Reinforcement Learning can also spot changes in how people, processes or physical devices are behaving. The Anomaly Detector service detects spikes, dips and other kinds of unexpected and rare events like a change in a trend using concepts like saliency. Microsoft uses that to monitor Windows, Office, Bing and about 200 other products.
The new Metrics Advisor (another Cognitive Service currently in preview) is built on top of the Anomaly Detector and is even more specific. It’s a pipeline that pulls in data, looks for anomalies in sensors, production processes or business metrics, does root cause analysis and recommends what actions to take, using RL to automatically customise the machine-learning mode. That makes it much easier to build systems for monitoring business metrics, AIOps for automating IT operations and predictive maintenance tools (or improve existing applications by adding those features).
Reaching the real world
These RL services use a specific type of algorithm known as a contextual bandit (inspired by slot machines in casinos that have different probabilities of paying out).
There are also other RL teams at Microsoft. For example, Project Bonsai combines a startup that Microsoft bought with an existing team building a simulation environment for flying drones (AirSim). “They do Reinforcement Learning by simulation in the cloud and deploy the learned model in real-world systems,” Langford explained. Helicopter manufacturer Bell is using Bonsai to train self-flying planes to land — that would be dangerous as well as expensive in the physical world.
The Project Bonsai platform simplifies machine teaching with deep reinforcement learning, allowing smarter autonomous systems to be trained and deployed.” data-credit=”Image: Microsoft” rel=”noopener noreferrer nofollow”>
The Project Bonsai platform simplifies machine teaching with deep reinforcement learning, allowing smarter autonomous systems to be trained and deployed.
Image: Microsoft
Reinforcement Learning systems can discover novel ways of doing something, but often you want to teach the system the best way to do it, or at least provide some high-level concepts so it isn’t wasting time on approaches that won’t work. The Bonsai platform aims to make machine teaching easier for people who are experts in the tasks the system needs to learn but aren’t data scientists, by treating the RL system as an apprentice. The domain experts build a simulation of the physical device it’s going to control and demonstrate tasks for it to imitate.
For example, instead of having human operators check a few Cheetos every now and then to make sure they’re the right shape and density, PepsiCo used Bonsai to build a RL system that uses a camera to monitor nearly all the snacks coming down the line, as well as how much water and cornmeal are going into the mix and then adjusts options like the speed of the screw that pushes the batter out, and the knife that cuts it into pieces. It’s the combination of lots of settings that keeps the Cheetos all the same even when one batch of cornmeal runs out and a new batch that might absorb more water is poured in; those are the kinds of complex relationships RL is good at.
PepsiCo used Project Bonsai to build an autonomous monitoring system for its Cheeto production line.” data-credit=”Image: Microsoft” rel=”noopener noreferrer nofollow”>
PepsiCo used Project Bonsai to build an autonomous monitoring system for its Cheeto production line.
Image: Microsoft
Reinforcement Learning can experiment in simulation, doing a day’s worth of Cheeto cooking in 30 seconds and then trying different options over and over again to see what works best. When they first used it to run a production line in a test factory, letting a few imperfect samples through to test it, PepsiCo allowed it to make suggestions that operators can accept or ignore; when it goes into production plants, it will be able to run autonomously, making changes to the machinery directly.
Transferring what’s learned in a simulation to the physical world isn’t always easy, so games — where RL first started showing good results — are still an important part of research, because advanced techniques are more likely to work there first. A simulation might not be accurate enough — that varies from application to application, Langford said. “But if you’re doing it in a game, the game is the world so the mismatch of reality and simulation doesn’t exist.”
Bonsai isn’t the only option for simulation-based Reinforcement Learning; you can build your own RL in the Azure Machine Learning service using common frameworks like Ray/RLLib and OpenAI Gym: customers are using that for problems in robotics, chemistry, gaming, online recommendations and advertising, Microsoft told us.
SEE: Equitable tech: AI-enabled platform to reduce bias in datasets released (TechRepublic)
Azure ML also allows data scientists to do what Langford calls “factual evaluation” — experimenting to see if you can improve on what the system has already learned.
“Something like the Personaliser service has a ‘data exhaust’. You can use this to test alternative policies; you can ask ‘what if I had done something else instead?’. You can take any custom policy and check to see if that would have performed better if you had deployed it when you’re collecting the data. Instead of trying things out for a couple of weeks in production, you can just try them out in simulation and you can compute the counterfactual in maybe a minute.”
That’s a huge productivity improvement, and it’s a technique Microsoft researchers use to improve their own services that customers can now use themselves.
Still an art
Although Reinforcement Learning has advanced enough to be used in production inside Microsoft and by customers, applying it to real-world problems can still be tricky. Getting the rewards right is crucial, Langford points out. “When using Reinforcement Learning, you have to decide what the reinforcement is, what the reward is, and defining what your reward function is often quite non-trivial.”
RL might be less subject to some kinds of machine-learning bias because the data scientist isn’t selecting the data set to train from, but “bias becomes a more subtle thing in some ways” Langford warns, particularly as part of setting up those reinforcement rewards.
Watching RL agents trying to learn to walk in a virtual world can be both amusing and disturbing because the wrong reward for movement can mean they fall over and push themselves along with their head.
“It’s critical when people are setting up the reward function that they are thinking about the short-term proxies which are best aligned with what their long-term goals are. It’s easy to deploy Reinforcement Learning in bad ways, so we need some wisdom in how we choose to deploy things,” Langford says.
Cramming more ads onto Bing would increase revenue as a short-term reward, but that would almost certainly have the wrong impact in the long run. “Deploy too many ads, everybody runs away and months later you have no traffic,” as Langford puts it.
It’s tempting to use short-term measures. “You’d like your reward to be as immediate as possible, because the more immediate it is the more quickly the system can learn, but you would like it to be well aligned with what you want in the long term. And finding shorter-term proxies for what you want in the longer term is really an art form still — we haven’t mastered that in any particular way.”
There’s a lot of research that will end up as new features further down the line.
“Reinforcement Learning is not nearly as settled as supervised learning. We have not quite, but pretty nearly, mastered contextual bandits. We know a good bit about how to incrementally improve Reinforcement Learning over episodes. Sometimes you can’t get an immediate reward; you have a reward, but you have to make several decisions before you see it. When you have that structure, a simple thing you can do is say ‘the last reward applies to every decision’, but it’s possible to improve on that in various ways. And I think we’re just discovering the foundations of model-based Reinforcement Learning, where the algorithm is building up a model of the world as it’s experiencing what’s going on.”
SEE: Equitable tech: AI-enabled platform to reduce bias in datasets released (TechRepublic)
Many RL techniques need fairly immediate rewards, but model-based RL can work with delayed rewards because it’s discovering the dynamics of the world. It can find even hard-to-discover rewards because it builds a model of the world, and then uses that to explore further and create a more accurate model each time.
“Imagine the reward is on top of a hill and you’re just doing a random walk. Typically you don’t get to the top of the hill — it’s exponentially unlikely,” Langford explains. “If you have more explicit model-based algorithms which are actively engaging in strategic exploration to get everywhere, then they will find that thing at the top of the hill. So there’s some real chance that we can discover how to work with very sparse rewards.”
With those kind of techniques, RL could help with many more problems, including advanced computer interfaces like voice recognition, handwriting recognition or even brain-computer interfaces. Handwriting and voice recognition currently use traditional supervised learning, but RL could go a long way towards personalising the recognition.
“You could imagine that you wear a wristband and have the computer learning what you mean when you’re twiddling your fingers in different ways,” Langford says. That could mean that instead of designing computer interfaces we shift to learning computer interfaces in the not-too-distant future. “There’s still a lot of work to be done there obviously, but I think working with computers can become much more natural.”
In fact, the biggest problem in applying Reinforcement Learning might be lack of imagination. A lot of things involve repeated decisions and fairly immediate feedback. “Of course there may be difficulties, but maybe there are breakthroughs — and maybe that changes the way the world works,” Langford concludes.
Data, Analytics and AI Newsletter
Learn the latest news and best practices about data science, big data analytics, and artificial intelligence.
Delivered Mondays
Sign up today
Also see
Source: https://www.techrepublic.com/article/microsofts-cutting-edge-machine-learning-tool-moves-from-the-lab-to-the-mainstream/