Feb. 11, 2021 — A game of chess has 20 possible opening moves. Imagine being asked to start a game with tens of millions of openings instead. That was the task assigned to Adam Friedman, a 2020 summer intern at NASA’s Goddard Space Flight Center in Greenbelt, Maryland. A chess champion in high school, Friedman analyzed his opponent—a deluge of data on the brightness changes of over 70 million stars.
Using traditional computational approaches, the task of sifting through and classifying these measurements could have taken months. With the use of machine learning, a form of artificial intelligence, this can be accomplished in seconds. Working with Brian Powell, a data scientist in the High Energy Astrophysics Science Archive Research Center at Goddard, Friedman trained a computer system to identify an important class of variable stars without explicitly programming it do so.
Machine learning allows computers to process and sort immense amounts of data automatically—just what was needed to sift through the torrent of stellar data. To do this, Powell created a neural network—a series of mathematical rules that attempt to recognize underlying relationships in data through a process that mimics, in a greatly simplified way, how the human brain works. For a neural network to function, though, it must be trained.
“The internship was about collecting training data,” Friedman said, “because machine learning works by collecting an incredibly large number of examples to train the model.”
NASA’s Transiting Exoplanet Survey Satellite (TESS) launched in April 2018 to find new worlds beyond our solar system, or exoplanets, by monitoring brightness changes in nearby stars. Since its launch, TESS has observed nearly the entire sky. Biweekly, the satellite beams back several thousand large pictures called full-frame images of a pre-planned section of the sky.
Astronomers use the data to construct light curves, graphs that show how a star’s brightness shifts over time. From the raw TESS data, Powell used the 129,000-core Discover supercomputer at NASA’s Center for Climate Simulation (NCCS) at Goddard to build millions of light curves.
“Thanks to support from NCCS, we were able to start building light curves in massive quantities. We have approximately 70 million now, with more on the way. Data science and machine learning can help drive these discoveries, allowing for high volumes of data to be sorted and processed faster and more accurately than ever before,” Powell said.
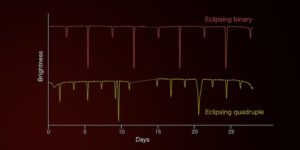
This illustration depicts light curves for a representative eclipsing binary (top) and one of the candidate eclipsing quadruple star systems identified by Adam Friedman. The extra dips caused by additional eclipses in the quadruple system result in a more complicated pattern. Credit: NASA’s Goddard Space Flight Center
Out of this enormous stack, Friedman wanted to identify eclipsing binaries, paired stars that alternately pass in front of, or transit, each other every orbit as seen from Earth. During each eclipse, the system dims as one star passes in front of the other, which produces a dip in its light curve. “The really useful feature of eclipsing binaries, and the reason that they are the backbone of astrophysics, is that they give us direct measurements of their fundamental properties, such as their mass and size,” said Veselin Kostov, a research scientist at Goddard and the SETI Institute in Mountain View, California. “And through these properties, we can directly measure distances to these systems. They afford us one of the very few opportunities to measure direct distances in the universe.”
NCCS also provided their Advanced Data Analytics PlaTform Graphics Processing Unit Cluster for running the neural network that Powell coded and Friedman trained.
Friedman could input a light curve and instruct the neural network to assign it to a particular category. After repeating this action thousands of times, the neural network began to recognize groups of light curves and suggest classifications based on the probability that a given curve fits into a given group. Friedman found example light curves for a broad range of star systems and input them until the network learned what each looked like and could identify new light curves autonomously. This allowed for a task that would have taken months on a modern desktop computer to be completed in a few seconds.
Machine learning vastly improves the efficiency of finding these star systems in tens of millions of TESS images by learning to identify the features of an eclipse and labeling the light curve accordingly. But Friedman soon noticed a quirk in some of the light curves the network had claimed were eclipsing binary candidates. They had extra dips.
Occasionally, star systems can have more than two components. If these stars eclipse each other, then the light curve will have additional dimmings that, at first glance, will appear at irregular intervals. Friedman discovered they were candidates for multistar systems and then began an exhaustive search for similar systems among the eclipsing binaries identified by the neural network. In total, Friedman found eight new candidate quadruple star systems. These cases are interesting because they provide insight into how multistar systems form and evolve.
Click here to read full announcement.
Source: Madison Arnold, NASA’s Goddard Space Flight Center
Source: https://www.hpcwire.com/off-the-wire/researcher-uses-machine-learning-to-classify-stellar-objects-from-satellite-data/