In 2020, few things went well and saw growth. Artificial intelligence was one of them, and healthcare was another one. As noted by ZDNet’s own Joe McKendrick recently, artificial intelligence remained on a steady course of growth and further exploration — perhaps because of the Covid-19 crisis. Healthcare was a big area for AI investment.
Today, the results of a new survey focusing precisely on the adoption of AI in healthcare are being unveiled. ZDNet caught up with Gradient Flow Principal Ben Lorica, and John Snow Labs CTO David Talby, to discuss findings and the state of AI in healthcare.
Leapfrogging — from pen and paper to AI
The survey was conducted by Lorica and Paco Nathan, and sponsored by John Snow Labs. A total of 373 respondents from 49 countries participated. A quarter of respondents (27%) held Technical Leadership roles. Here are some key findings, with additional insights from Lorica and Talby.
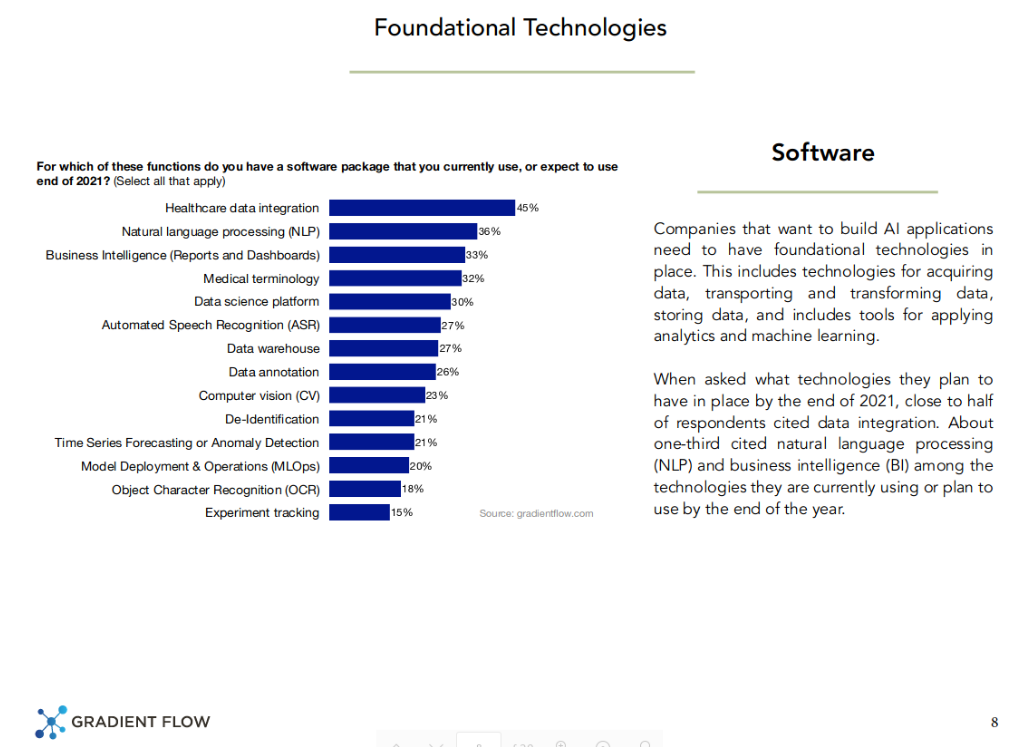
When asked what technologies they plan to have in place by the end of 2021, almost half of respondents cited data integration. About one-third cited natural language processing (NLP) and business intelligence (BI) among the technologies they are currently using or plan to use by the end of the year.
To us, this seemed a bit puzzling. As we’ve repeatedly noted, data integration is a prerequisite for analytics, machine learning and AI. Could it be that only half the organizations in healthcare have solved data integration, and yet they plan to embark on NLP and machine learning efforts?
Lorica noted that this should perhaps be seen more in ordinal rather than in a numerical way. In other words, respondents may have ranked technologies in order of importance for them. In that sense, he went on to add, it makes sense that data integration comes on top. And it also makes sense that NLP comes in second, as Talby went on to show.
For the last 10 years, Talby noted, what was done in healthcare was a huge deployment of Electronic Medical Records (EMRs). That comes down to taking what people were doing in paper, and digitizing it. What people are now discovering, he went on to add, is that all the interesting clinical information is still in text. Very little is actually structured, and in healthcare, that is more so than in other industries:
“Even for asking fairly simple questions, like getting all patients with a certain condition, very often the way you still do it, is you have humans — nurses and doctors — who sit down and read things one by one. Because the majority of the relevant clinical data is in free text”.
It’s not that there is a complete lack of structured data — databases — in healthcare, Talby clarified. For things such as supply chains and billing, databases and software systems and BI reports are used. But as far as the actual domain-specific knowledge is concerned, things are very much text-centric.
Doctors already feel they spend too much time in administration tasks. The average doctor spends about 3 hours per day filling in information in EMRs, so there’s no way you can get them to fill in combo boxes and checkboxes. It’s just not going to happen, Talby thinks.
But NLP, and the fact that in the last couple of years we’re starting to have algorithms that at least match human specialist capability in extracting this kind of information, may be a game changer. It’s essentially leapfrogging — from pen and paper to AI, letting the experts do what they do best.
Automating drug research with algorithms and knowledge graphs
Survey respondents were classified as to the level of maturity their organizations have in using AI technology in 3 different segments — Exploring, Early Stage, and Mature. When reporting on the users of the applications their organizations are building, clinicians, healthcare providers, and patients were the largest groups reported by respondents, at 54%, 45%, and 34% respectively.
This is not surprising, given these are presumably the largest user groups in the industry. What we found noteworthy, however, is the unusually high percentage of applications aimed at drug development professionals in mature organizations: 43%, over 21% on average.
Drug development, especially the very early stages of finding candidates, has quickly become a software problem, Talby noted. For biology or biochemistry PhDs, working at a drug company for 40 years, reading research papers and trying to find correlations was a common career path.
Today, algorithms can do this very effectively, even more effectively than human experts. It is possible to look at all the academic papers that are out there, all the patents that are submitted, and all the investment disclosures, every week.
It is possible to build knowledge graphs automatically. To combine drugs and molecules. To explore side effects and effectiveness. There’s a number of companies building drug pipelines, leveraging medical ontologies, gene ontologies, gene products, academic literature.
Software-based research alone can even get to pre-phase one trials, Talby noted. Molecules with potential can be patented, then sold and licensed to the large pharma companies. Potential may mean a 5% chance of success, but that is still orders of magnitude higher than what was hitherto an acceptable starting point:
“This industry was very manual and human intensive. Where really your competitive differentiator was — look, I have 500 PhDs, who just do this day to day. We’re at a point where within three, four years, you can come and say, hey, I can actually do better than all of them almost, with software”.
The fact that more mature companies seem to be doing this more may be because this is a use case that requires some sophistication, or because it’s an acceleration of a revenue stream they was already in place.
Healthcare is special
Lorica mentioned that the relative democratization of AI, in the sense of having open source tools, may mean people who may not be experts in machine learning can start playing around with some of the techniques. In addition, the existence of benchmarks also helps. In computer vision, there’s a famous benchmark that really led to a lot of progress called ImageNet. Now there are similar benchmarks in drug discovery as well.
The use of open source and cloud, which often goes hand in hand, is a cross-industry phenomenon. Healthcare is not different in that respect, although it does have its own traits. Most notably, it’s a regulated industry. As Lorica noted, people in this industry have historically been aware of compliance when considering cloud vendors.
Talby added another dimension to this. if people want patient data, first off, often it’s just illegal to share it without patient consent, and even then, data has to be de-identified and anonymized. So if organizations that work with Amazon or Google want to enable them to improve their machine learning models, they would have to get consent.
Furthermore, this is actually a revenue stream for healthcare companies. If a pharma company strikes a deal to provide access to 50000 patient records, for example, one time accesses for a six month project could mean half a million dollars to access the data, Talby noted:
“When AWS said, just send us your notes to AWS Comprehend Medical, and by the way, we also use your notes to train our models..That was laughable for the healthcare and pharma industry. That was like — we pay you for this service? That’s not how it works”.

Cloud providers had to adjust, Talby noted. This is not a “move fast and break things” industry, and for good reason. However, technical advances such as transfer learning may mean that the hard tradeoff between privacy and accuracy will soften. Large data sets may not be needed to train and tune models, and Talby posited state of the art can be achieved without the need for millions of records.
Speaking of state of the art, another interesting finding in the survey was the low utilization of different types of data. Text and structured data are prevalent, medical images and time series data are also used, but audio and video data are still mostly untapped.
As Lorica noted, audio and video tend to be more advanced capabilities. They also need labeling by domain experts, and this is not easy to come by in healthcare. Notably, however, early stage organizations seem to be using audio and video far more. This may mean we are about to see more audio and video data being utilized soon.
In general, in healthcare like in all other industries, we’re still in the early stages of AI adoption. Outside of the most advanced technology companies, there’s still a lot of digitization and coming to terms with the limitations of these models, what they can do and what some of the pitfalls are.
In healthcare, people are more likely to be more more careful than in other industries. It’s also one of the more conscious industries in terms of the need for transparency, explainability, and fairness. In that respect, healthcare may set an example for other industries.