NVIDIA
NVIDIA
NVIDIA GTC is the premier annual conference for developers, scientists, and businesses interested in machine learning or artificial intelligence. According to NVIDIA CEO and founder Jensen Huang, over 100,000 attended this year’s virtual event. Following tradition, NVIDIA made GTC 2021 a stage for many significant ML, AI, networking, and data center announcements. One of Huang’s most exciting announcements was the development and 2023 deployment of a newly designed AI platform robust enough to accommodate the training of future AI models that almost rival the number of synapses in a human brain.
Massive model sizes
NVIDIA
NVIDIA
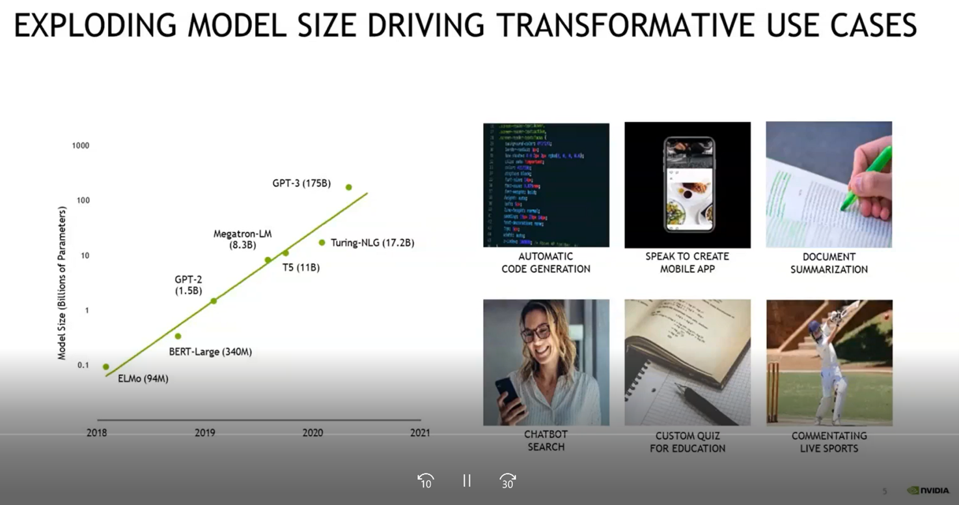
According to Ian Buck, NVIDIA’s GM and VP of Accelerated Computing, there has been dramatic growth in AI models’ size, particularly for language (NLP) models. Initially, AI models consisted of simple objects used with computer vision, such as animals, objects, and scenes. It is also important to remember that training large models consumes large amounts of power.
Buck said, “The real test for artificial intelligence is its ability to understand the language, what people are saying, what the words mean, and being able to reply humanly with insight. At this point, there’s no limit to the size of the neural networks that can be used to solve it.”
As a comparison, in 2018, Google published a transformer-based machine learning technique for natural language processing (NLP) pre-training. This early model was called BERT and had 340 million connections. BERT was open-source and developed for a wide range of search engine-related tasks such as answering questions and language inference.
MORE FOR YOU
Today, models like Open AI’s GPT-3 with up to 175 billion connections have dwarfed BERT. That many connections may sound like a lot but compared to the human brain with 150 trillion connections, it is relatively small. Even so, today’s networks can do many valuable things, such as facilitating the use of our cell phones, acting as intelligent chatbots, performing document analysis, and other tasks.
A new architecture is needed for future models
NVIDIA
NVIDIA
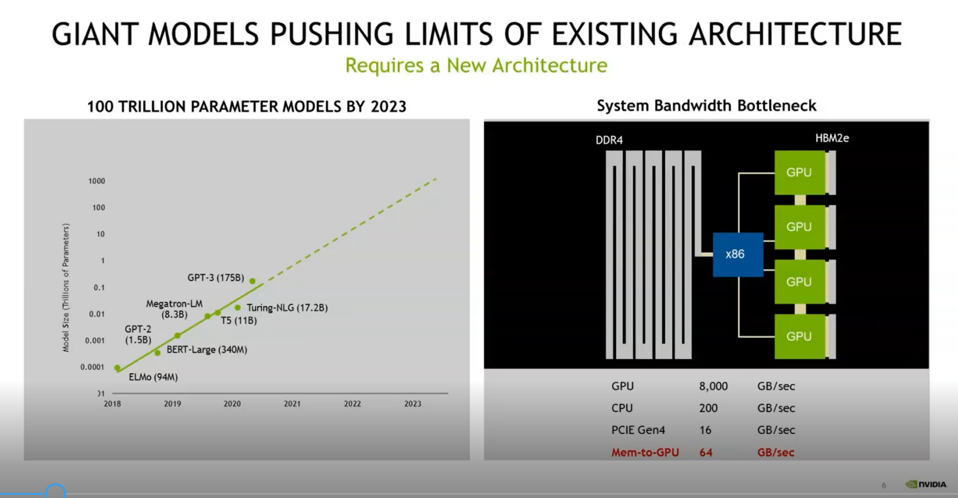
As AI model sizes continue to grow, by 2023 NVIDIA believes that models will have 100 trillion or more connections. Models of that size will exceed the technical capabilities of existing platforms.
Ian Buck looks at the challenge as an opportunity rather than a problem. He describes the situation this way: “When we look at training requirements of 100 trillion parameter models, we can see some bottlenecks in today’s system architectures. HBM2E, which we use to store all the information on the neural network, is great, it is amazingly fast. An A100 80 gig GPU has over two terabytes of bandwidth that keep the AI computations flowing and moving very quickly. But we’re going to run out of space. These models, even a GPT-3, can’t be trained on a single GPU. We have to train across multiple GPUs and multiple nodes to make it work. And in fact, the bottlenecks are starting to show up with things like PCIe, [where] we have a very narrow connection between the CPU and the GPU.”’
To meet the challenge of training future models with one trillion parameters, NVIDIA announced a new CPU-GPU platform architecture at GTC 2021 – NVIDIA calls it Grace.
NVIDIA Grace
NVIDIA
NVIDIA
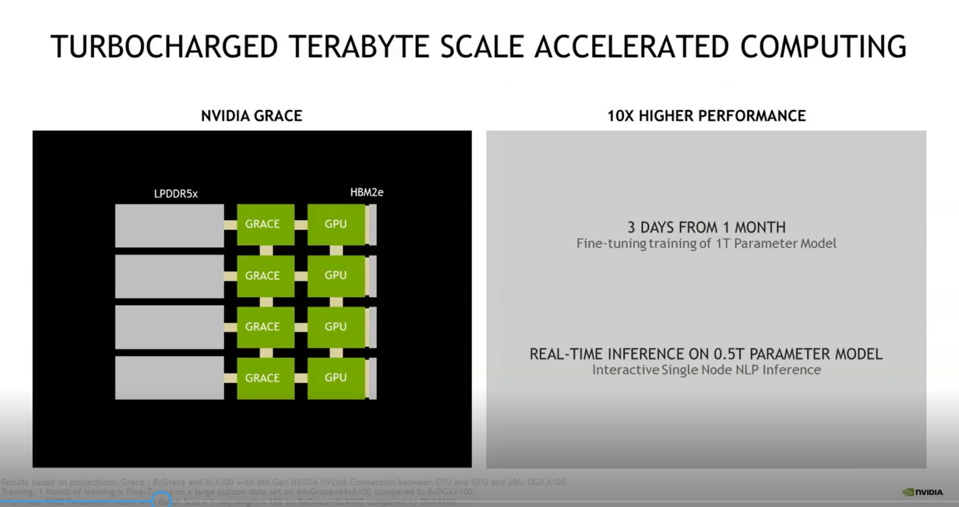
NVIDIA has not yet released detailed architecture information on the newly announced Grace Module. However, we know that it is a next-generation ARM Neoverse core that will become available in 2023. It is planned for each of four Grace ARM CPUs to be coupled via NVLink to a yet-to-be-announced new GPU generation.
A vital feature of the grace module is a breakthrough CPU designed and built by NVIDIA for giant scale AI and HPC applications. The CPU sits directly next to existing GPUs with a high-speed interconnect between the two processors. The interconnecting link has a bandwidth of 900 gigabytes/second, that is 14X greater than today. It will allow trillion connection models to be trained and perform inference on a real-time basis.
According to Buck, because the bus is so wide, it is possible to provide a continuous unified address space for the entire system. As a coherent cache architecture, both the CPU and GPU can maintain coherent caches provides the programmer and developer with single, fast memory space. Surprisingly, the GPU will be able to access the CPU memory just as fast as the CPU can, which unifies the memory architecture.
Also, Grace will have a CPU to CPU NVLink to span across CPUs. That is also coherent for a single image across multiple grace modules at 600 gigabytes/second, double the speed of what is available in x86 today.
Additionally, NVIDIA designed a new memory technology for data centers called LDDR5X. The memory was previously used in the mobile embedded space but reworked to create a data center version that includes all the data center hardening features like ECC protection. It has over 500 gigabytes/second of memory bandwidth which is double that of traditional DDR.
Because large models require an immense amount of power, it is also important to note that LDDR is 10X more energy efficient than DDR.
Grace powers the world’s fastest supercomputer
NVIDIA already has a customer for Grace. The Swiss National Supercomputing Center (CSCS), Hewlett Packard Enterprise and NVIDIA, announced building the world’s most powerful AI-capable supercomputer – ALPS. It will deliver 20 exaflops of AI.
ALPS will come online in 2023 simultaneously, Grace and the next generation of NVIDIA GPUs will be available. ALPS will replace the existing Piz Daint supercomputer and serve as a general-purpose system open to researchers’ broad community in Switzerland and the rest of the world. It will enable research on a wide range of fields, including climate and weather, materials sciences, astrophysics, computational fluid dynamics, life sciences, molecular dynamics, quantum chemistry, and particle physics, and domains like economics and social sciences.
As a reference point, with NVIDIA Grace and the new generation of GPUs, Alps will have the capability to train GPT-3, one of the world’s largest natural language processing model, in only two days — 7x faster than NVIDIA’s 2.8-AI exaflops Selene supercomputer, currently recognized as the world’s leading supercomputer for AI by MLPerf.
Analyst notes
- NVIDIA’s interest in quantum is understandable. Quantum Natural Language Processing (QNLP) deals with the design and implementation of NLP models intended to be run on quantum hardware. Cambridge Quantum Computing recently published a paper indicating favorable NLP results with today’s noisy quantum computers. It is only a matter of time until quantum computing can scale to a point useful for NLP.
- The NVIDIA roadmap indicates the development of Grace 2 in 2025. At this point, we can only speculate on new features other than there is a high likelihood there will be an increase of Grace-GPU pairs from four to a more significant number, perhaps as high as eight.
- Given ALPS record-breaking 20 exaflops, and its considerable advantage over other exascale computers, I expect there will soon be other sales and projects announcements utilizing Grace.
- NVIDIA made many other announcements at GTC 2021. I will cover some additional ones about NVIDIA’s AI platform later.
- Almost everyone interested in AI is curious to determine what can be done with 100 trillion parameter models. One thing is for sure – we will see some amazing research.
Note: Moor Insights & Strategy writers and editors may have contributed to this article.
Moor Insights & Strategy, like all research and analyst firms, provides or has provided paid research, analysis, advising, or consulting to many high-tech companies in the industry, including 8×8, Advanced Micro Devices, Amazon, Applied Micro, ARM, Aruba Networks, AT&T, AWS, A-10 Strategies, Bitfusion, Blaize, Box, Broadcom, Calix, Cisco Systems, Clear Software, Cloudera, Clumio, Cognitive Systems, CompuCom, Dell, Dell EMC, Dell Technologies, Diablo Technologies, Digital Optics, Dreamchain, Echelon, Ericsson, Extreme Networks, Flex, Foxconn, Frame (now VMware), Fujitsu, Gen Z Consortium, Glue Networks, GlobalFoundries, Google (Nest-Revolve), Google Cloud, HP Inc., Hewlett Packard Enterprise, Honeywell, Huawei Technologies, IBM, Ion VR, Inseego, Infosys, Intel, Interdigital, Jabil Circuit, Konica Minolta, Lattice Semiconductor, Lenovo, Linux Foundation, MapBox, Marvell, Mavenir, Marseille Inc, Mayfair Equity, Meraki (Cisco), Mesophere, Microsoft, Mojo Networks, National Instruments, NetApp, Nightwatch, NOKIA (Alcatel-Lucent), Nortek, Novumind, NVIDIA, Nuvia, ON Semiconductor, ONUG, OpenStack Foundation, Oracle, Poly, Panasas, Peraso, Pexip, Pixelworks, Plume Design, Poly, Portworx, Pure Storage, Qualcomm, Rackspace, Rambus, Rayvolt E-Bikes, Red Hat, Residio, Samsung Electronics, SAP, SAS, Scale Computing, Schneider Electric, Silver Peak, SONY, Springpath, Spirent, Splunk, Sprint, Stratus Technologies, Symantec, Synaptics, Syniverse, Synopsys, Tanium, TE Connectivity, TensTorrent, Tobii Technology, T-Mobile, Twitter, Unity Technologies, UiPath, Verizon Communications, Vidyo, VMware, Wave Computing, Wellsmith, Xilinx, Zebra, Zededa, and Zoho which may be cited in blogs and research.