At the recent QCon Plus online conference, Katharine Jarmul gave a talk on federated machine learning titled “Machine Learning at the Edge.” She covered federated ML architectures and use cases, discussed pros and cons of federated ML, and presented tips on how to decide whether federated ML is a good solution for a given problem.
Jarmul, who runs Kjamistan, a data science consulting company, began by discussing use cases for ML on edge or Internet of Things (IoT) devices, and how constraints of these devices require a new way of thinking about the ML process. She then presented an overview of federated ML. Next, she discussed Federated Learning of Cohorts (FLoCs), a federated ML application developed by Google. Finally, she presented several benefits and weaknesses of federated ML, and walked through a flowchart developers can use to decide when federated ML is a good choice for their problem. In the post-presentation Q&A session, Jarmul noted that one side effect of federated ML could be a mindset change for data teams:
It puts the onus on the data team to think a little bit more about the problem they’re trying to solve. Unfortunately, a common experience of data teams is that they have all this data, but none of it answers the question they want to ask. Maybe [federated ML] is helpful in terms of thinking about asking the questions first and then collecting the right data.
Jarmul began by describing the problem domain of machine learning with a distributed system of embedded devices; for example, microcontrollers on a fleet of electric scooters. These devices can collect a lot of data, but using the data to train ML models can present many challenges: because they may not have stable internet connections or much local memory and storage, collecting the data from these devices for training or inference in centralized locations may be impractical. An alternative approach is federated machine learning.
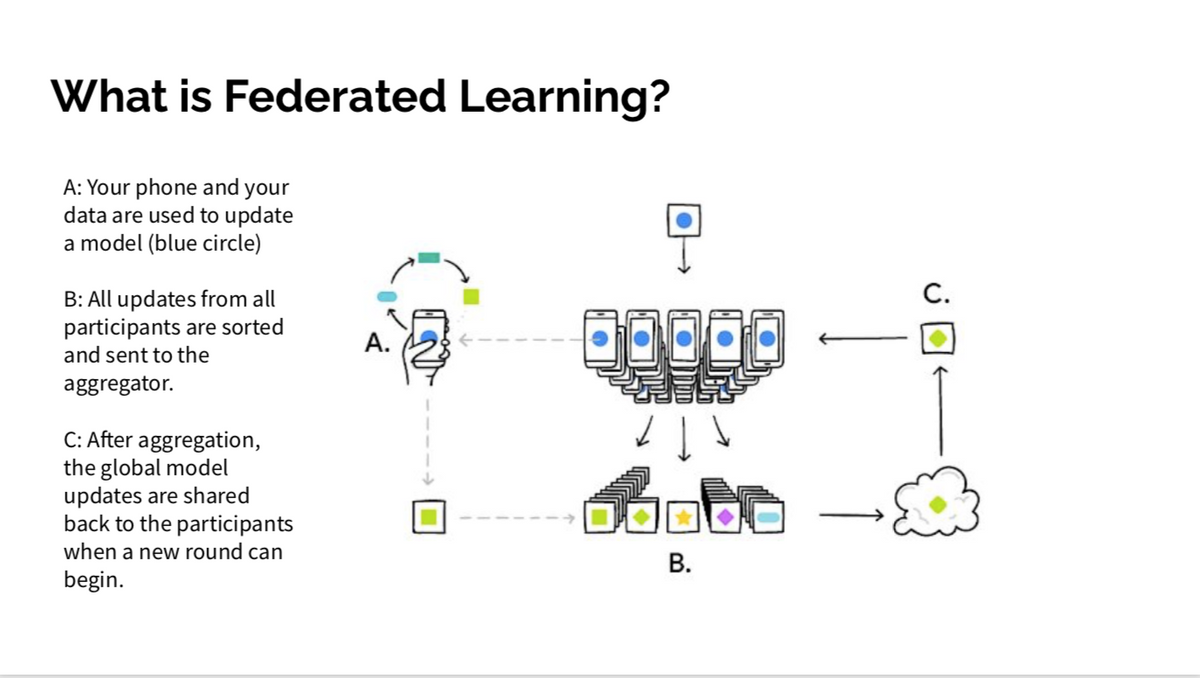
Federated ML was first proposed by researchers at Google in 2016. The general idea is that instead of collecting training data from all devices to update a model, each device retains its own data and calculates updates to its local copy of the model. Each device then sends its updates to a central location, where they are aggregated and applied to the central server’s model, which is updated and deployed to all remote devices. Because only the model updates are communicated from the edge devices instead of raw training data, federated ML increases privacy while reducing network traffic.
Next, Jarmul covered an application of federated ML called Federated Learning of Cohorts (FLoCs). Also developed by Google as part of their Privacy Sandbox initiative, FLoCs are a way to “enable interest-based advertising on the web,” by grouping users into cohorts with similar interests. In this scheme, a user is assigned an initial cohort. Over time, the browser will “use machine learning algorithms to develop a cohort based on the sites that an individual visits.” However, the browser will not send raw data about the sites to a central location; instead, the browser simply updates the central server with that user’s cohort. Jarmul noted that although federated ML often is considered a way to improve privacy, it is not guaranteed, and FLoCs in particular has been criticized by the Electronic Frontier Foundation for its privacy flaws.
She then described several benefits and weaknesses of federated ML. One key benefit is that there is no centralized data collection, as the raw data never leaves the edge device; however, this requires that the data on the device be standardized, that is, converted to a vector or matrix form, so that it can be used for updating a model. Another benefit is that the data will likely be more diverse; one drawback of that, though, is that the data may be unbalanced. Deploying models directly to the edge devices has the benefit of real-time local inference, even without network connections. However, this means that developers must make sure that end users cannot extract proprietary or sensitive information from the model. Finally, while federated ML offers the potential for more privacy, it is not guaranteed. Federated ML can still potentially leak information unless developers are careful and use techniques such as differential privacy or gradient clipping.
Jarmul concluded her presentation with a flowchart for helping developers decide if federated ML is a good choice for their application. First, she cautioned that if a developer is “looking for tried and true,” federated ML is likely not a good choice. The next question to consider is whether the data used for training is “standardized” and whether the edge devices are powerful enough to run learning algorithms. If not, Jarmul recommended distributed data analysis: techniques for querying data on devices and sending aggregates back to a central location for the data science team to use to answer questions. If federated ML is a viable option, Jarmul then recommended considering whether to use a centralized or clustered federation. A centralized solution “will have less complexity and will be easier to set up.” However, if the existing distributed system is already clustered in some way, that might be easier to use. Finally, Jarmul recommended including privacy and security experts in design discussions, and considering contingency plans for loss of network connectivity
After the presentation, Jarmul answered several questions from the audience. Conference track host Sergey Fedorov asked about the hardware requirements for edge devices to perform federated ML. She replied that the key feature was the ability to do vector arithmetic, and noted that Apple in particular has been shipping devices with “quite performant” chips. She also suggested that for less-powerful hardware, developers might consider using more “classic” ML algorithms instead of deep learning models. An audience member asked about the differences between iOS and Android devices for federated ML. Jarmul replied that iOS is probably ahead of Android in capabilities because of Apple’s controlled approach to hardware, and that iOS has support for differential privacy built in. She did note, however, that Android devices would support federated ML libraries for Google’s TensorFlow deep learning framework, which would be helpful for developers.
Jarmul also shared several links to federated ML resources, including TensorFlow Federated; PySyft, which supports both TensorFlow and PyTorch; IBM federated learning, a Python library for federated learning with various model types; and Federated AI, an distributed learning ecosystem released by WeBank.
Source: https://www.infoq.com/news/2021/12/jarmul-ml-edge/