Key Takeaways
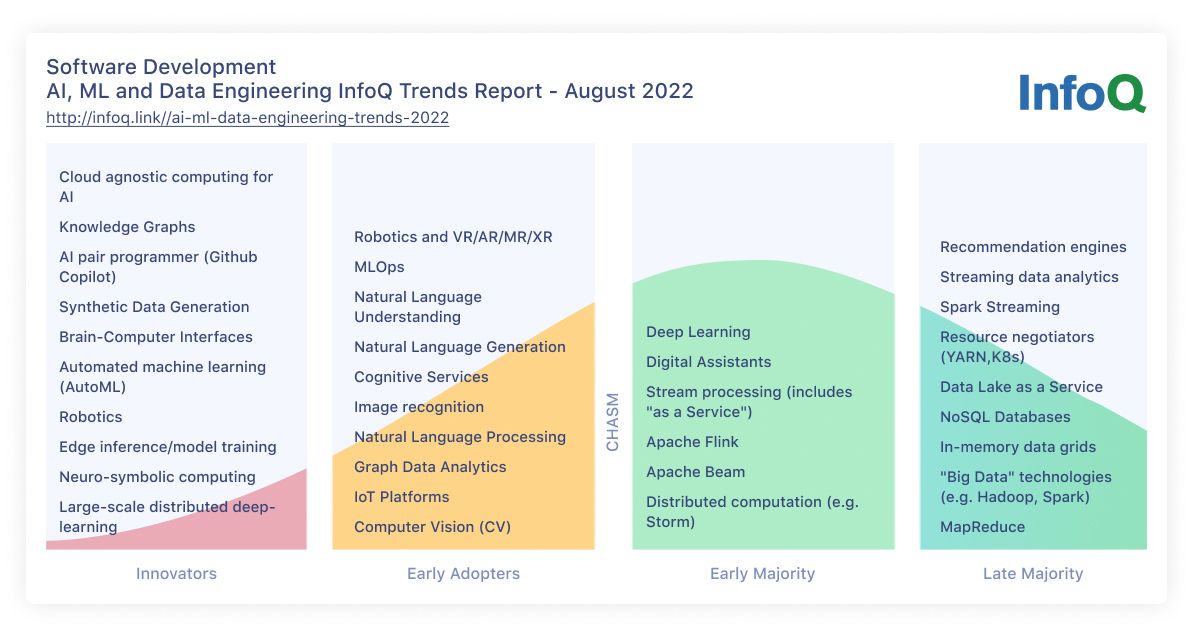
Natural Language Understanding (NLU) and Natural Language Generation (NLG) have been promoted to the early adopters category.
Since last year, deep learning solutions and technologies have seen wider adoption in organizations, so we are moving deep learning from early adopters to the early majority category.
Streaming data analytics and technologies like Spark Streaming have been moved to the late majority category.
Resource Negotiators like YARN and container orchestration technologies like Kubernetes are now in the late majority category.
New entrants in the innovators category include Cloud agnostic computing for AI, Knowledge Graphs, AI pair programmer (like Github Copilot), and Synthetic Data Generation.
New entries in the early adopters category include Robotics and Virtual Reality and related technologies (VR/AR/MR/XR) and MLOps.
This article is a summary of the AI, ML, and Data Engineering InfoQ Trends 2022 podcast and highlights the key trends and technologies in the areas of AI, ML, and Data Engineering.
In this annual report, the InfoQ editors discuss the current state of AI, ML, and data engineering and what emerging trends you as a software engineer, architect, or data scientist should watch. We curate our discussions into a technology adoption curve with supporting commentary to help you understand how things are evolving.
In this year’s podcast, InfoQ editorial team was joined by an external panelist Dr. Einat Orr, co-creator of the open source project LakeFS, and a co-founder and CEO at Treeverse, as well as a speaker at the recent QCon London conference.
The following sections in the article summarize some of these trends and where different technologies fall in the technology adoption curve.
The Rise of Natural Language Understanding and Generation
We see Natural Language Understanding (NLU) and Natural Language Generation (NLG) technologies as early adopters. The InfoQ team has published about recent developments in this area including Baidu’s Enhanced Language RepresentatioN with Informative Entities (ERNIE), Meta AI’s SIDE, as well as Tel-Aviv University’s Standardized CompaRison Over Long Language Sequences (SCROLLS).
We have also published several NLP-related developments such as Google Research team’s Pathways Language Model (PaLM), EleutherAI’s GPT-NeoX-20B, Meta’s Anticipative Video Transformer (AVT), and BigScience Research Workshop’s T0 series of NLP models.
Deep Learning: Moving to Early Majority
Last year, as we saw more companies using deep learning algorithms, we moved deep learning from the innovator to the early adopter category. Since last year, deep learning solutions and technologies have been widely used in organizations, so we are moving it from early adopter to early majority category.
There were several publications on this topic as podcasts (Codeless Deep Learning and Visual Programming), articles (Institutional Incremental Learning based Deep Learning Systems, Loosely Coupled Deep Learning Serving, and Accelerating Deep Learning with Apache Spark and NVIDIA GPUs) as well as news items including BigScience Large Open-science Open-access Multilingual Language Model (BLOOM) from BigScience research workshop, Google AI’s deep learning language model called Minerva and OpenAI’s open-source framework called Video PreTraining (VPT).
Vision Language Models
Interesting developments in image processing related AI models also include DeepMind’s Flamingo, an 80B parameter vision-language model (VLM) that combines separately pre-trained vision and language models and answers users questions about input images and videos.
Google’s Brain team has announced Imagen, a text-to-image AI model that can generate photorealistic images of a scene given a textual description.
Another interesting technology, digital assistants, is also now in the early majority category.
Streaming Data Analytics: IoT and Real-Time Data Ingestion
Streaming first architectures and streaming data analytics have seen increasing adoption in various companies, especially in the IoT and other real-time data ingestion and processing applications.
Sid Anand’s presentation on building & operating high-fidelity data streams and Ricardo Ferreira’s talk on building value from data in-motion by transitioning from batch data processing to stream based data processing are excellent examples of how stream based data processing is a must-have in strategic data architectures. Also, Chris Riccomini in his article, The Future of Data Engineering, discussed the important role stream processing plays in the overall data engineering programs.
Chip Huyen spoke at last year’s QCon Plus online conference on Streaming-First Infrastructure for Real-Time ML and highlighted the advantages of a streaming-first infrastructure for real-time and continual machine learning, the benefits of real-time ML, and the challenges of implementing real-time ML.
As a reflection of this trend, streaming data analytics and technologies, such as Spark Streaming have been moved to late majority. Same for Data Lake as a Service which gained further adoption last year with products like Snowflake.
AI/ML Infrastructure: Building for Scale
Highly scalable, resilient, distributed, secure, and performant infrastructure can make or break the AI/ML strategy in an organization. Without a good infrastructure as the foundation, no AI/ML program can be successful in the long term.
At this year’s GTC conference, NVIDIA announced their next-generation processors for AI computing, the H100 GPU and the Grace CPU Superchip.
Resource Negotiators like YARN and container orchestration technologies like Kubernetes are also now in the late majority category. Kubernetes has become the de facto standard for cloud platforms and multi-cloud computing is gaining attention in deploying applications to the cloud. Technologies like Kubernetes can be the enablers for automating the complete lifecycle of AI/ML data pipelines including the production deployments and post-production support of the models.
We also have a few new entrants in the Innovators category. These include Cloud agnostic computing for AI, Knowledge Graphs, AI pair programmer (like Github Copilot), and Synthetic Data Generation.
Knowledge Graphs continue to leave a large footprint in the enterprise data management landscape with real-world applications for different use cases including data governance.
ML-Powered Coding Assistants: GitHub Copilot
GitHub Copilot, announced last year, is now prime time-ready. Copilot is an AI-powered service that helps developers write new code by analyzing already existing code as well as comments. It helps with the overall developers’ productivity by generating basic functions instead of us writing those functions from scratch. Copilot is the first among many solutions to come out in the future, to help with AI-based pair programming and automate most of the steps in the software development lifecycle.
Nikita Povarov, in the article AI for Software Developers: a Future or a New Reality, wrote about the role of AI developer tools. AI developers may attempt to use algorithms to augment programmers’ work and make them more productive; in the software development context, we’re clearly seeing AI both performing human tasks and augmenting programmers’ work.
Synthetic Data Generation: Protecting User Privacy
On the data engineering side, synthetic data generation is another area that’s been gaining a lot of attention and interest since last year. Synthetic data generation tools help to create safe, synthetic versions of the business data while protecting customer privacy.
Technologies like SageMaker Ground Truth from AWS that users can now create labeled synthetic data with. Ground Truth is a data labeling service that can produce millions of automatically labeled synthetic images.
Data quality is critical for AI/ML applications throughout the lifecycle of those apps. Dr. Einat Orr spoke at QCon London Conference on Data Versioning at Scale and discussed the importance of data quality and versioning of large data sets. Version control of the data allows us to ensure we can reproduce a set of results, better lineage between the input and output data sets of a process or a model, and also provides the relevant information for auditing.
Ismaël Mejía at the same conference talked about how to adopt open source APIs and open standards to more recent data management methodologies around operations, data sharing, and data products that enable us to create and maintain resilient and reliable data architectures.
In another article Building End-to-End Field Level Lineage for Modern Data Systems, authors discuss data lineage as a critical component of the data pipeline root cause and impact analysis workflow. To better understand the relationship between source and destination objects in the data warehouse, data teams can use field-level lineage. Automating lineage creation and abstracting metadata down to the field-level cuts down on the time and resources required to conduct root cause analysis.
Early adopters category also includes new entries. These include Robotics, Virtual Reality, and related technologies (VR/AR/MR/XR) as well as MLOps.
MLOps: Combining ML and DevOps Practices
MLOps has been getting a lot of attention in companies to bring the same discipline and best practices that DevOps offers in the software development space.
Francesca Lazzeri, at her QCon Plus Conference, spoke about MLOps as the most important piece in the enterprise AI puzzle. She discussed how MLOps empowers data scientists and app developers to help bring the machine learning models to production. MLOps enables you to track, version, audit, certify, reuse every asset in your machine learning lifecycle, and provides orchestration services to streamline managing this lifecycle.
MLOps is really about bringing together people, processes, and platforms to automate machine learning-infused software delivery and also provide continuous value to our users.
She also wrote about what you should know before deploying ML applications in production. Key takeaways include using open source technologies for model training, deployment, and fairness and automating the end-to-end ML lifecycle with machine learning pipelines.
Monte Zweben talked about Unified MLOps to bring together core components like Feature Stores and model deployment.
Other key trends discussed in the podcast (LINK) are:
In AI/ML applications, the transformer is still the architecture of choice.
ML models continue to get bigger, supporting billions of parameters (GPT-3, EleutherAI’s GPT-J and GPT-Neo, Meta’s OPT model).
Open source image-text data sets for training things like CLIP or DALL-E are enabling data democratization to give people the power to take advantage of these models and datasets.
The future of robotics and virtual reality applications are going to be mostly implemented in the metaverse.
AI/ML compute tasks will benefit from the infrastructure and cloud computing innovations like multi-cloud and cloud-agnostic computing.
For more information, check out the 2022 AI, ML, and Data Engineering podcast recording and transcript as well as the AI, ML & Data Engineering content on InfoQ.
QCon San Francisco Software Development Conference Oct 24-28, 2022
QCon San Francisco brings together the world’s most innovative senior software engineers, architects and team leads across multiple domains to share their real-world implementation of emerging trends and practices.
Uncover emerging software trends and practices to solve your complex engineering challenges, without the product pitches.
Attend in-person on October 24-28, 2022
Register now
About the Authors
Srini Penchikala
Show moreShow less
Dr Einat Orr
Show moreShow less
Rags Srinivas
Show moreShow less
Roland Meertens
Show moreShow less
Anthony Alford
Show moreShow less
Daniel Dominguez
Show moreShow less
Source: https://www.infoq.com/articles/ai-ml-data-engineering-trends-2022/