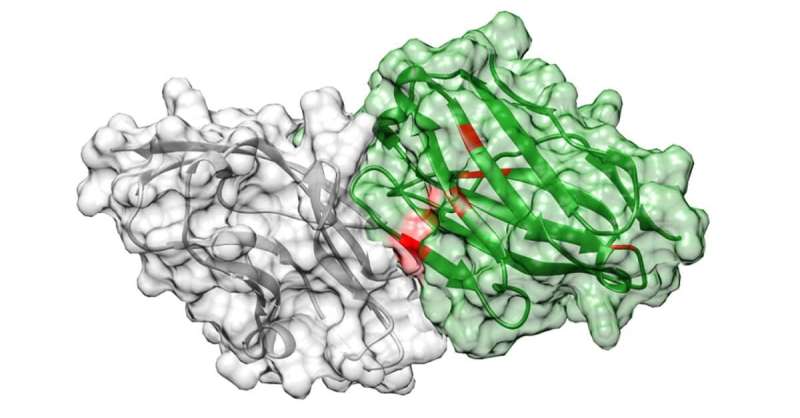
The AI-based approach successfully identified a new antibody, shown here tightly bound to its target, PD-L1. Credit: UC San Diego Health Sciences
Scientists at University of California San Diego School of Medicine have developed an artificial intelligence (AI)-based strategy for discovering high-affinity antibody drugs.
In the study, published January 28, 2023 in Nature Communications, researchers used the approach to identify a new antibody that binds a major cancer target 17-fold tighter than an existing antibody drug. The authors say the pipeline could accelerate the discovery of novel drugs against cancer and other diseases such as COVID-19 and rheumatoid arthritis.
In order to be a successful drug, an antibody has to bind tightly to its target. To find such antibodies, researchers typically start with a known antibody amino acid sequence and use bacterial or yeast cells to produce a series of new antibodies with variations of that sequence. These mutants are then evaluated for their ability to bind the target antigen. The subset of antibodies that work best are then subjected to another round of mutations and evaluations, and this cycle repeats until a set of tightly-binding finalists emerges.
Despite this long and expensive process, many of the resulting antibodies still fail to be effective in clinical trials. In the new study, UC San Diego scientists designed a state-of-the-art machine learning algorithm to accelerate and streamline these efforts.
The approach starts similarly, with researchers generating an initial library of about half a million possible antibody sequences and screening them for their affinity to a specific protein target. But instead of repeating this process over and over again, they feed the dataset into a Bayesian neural network which can analyze the information and use it to predict the binding affinity of other sequences.
“With our machine learning tools, these subsequent rounds of sequence mutation and selection can be carried out quickly and efficiently on a computer rather than in the lab,” said senior author Wei Wang, Ph.D., professor of Cellular and Molecular Medicine at UC San Diego School of Medicine.
One particular advantage of their AI model is its ability to report the certainty of each prediction. “Unlike a lot of AI methods, our model can actually tell us how confident it is in each of its predictions, which helps us rank the antibodies and decide which ones to prioritize in drug development,” said Wang.
To validate the pipeline, project scientists and co-first authors of the study Jonathan Parkinson, Ph.D., and Ryan Hard, Ph.D., set out to design an antibody against programmed death ligand 1 (PD-L1), a protein highly expressed in cancer and the target of several commercially available anti-cancer drugs. Using this approach, they identified a novel antibody that bound to PD-L1 17 times better than atezolizumab (brand name Tecentriq), the wild-type antibody approved for clinical use by the U.S. Food and Drug Administration.
The researchers are now using this approach to identify promising antibodies against other antigens, such as SARS-CoV-2. They are also developing additional AI models that analyze amino acid sequences for other antibody properties important for clinical trial success, such as stability, solubility and selectivity.
“By combining these AI tools, scientists may be able to perform an increasing share of their antibody discovery efforts on a computer instead of at the bench, potentially leading to a faster and less failure-prone discovery process,” said Wang. “There are so many applications to this pipeline, and these findings are really just the beginning.”
More information:
Jonathan Parkinson et al, The RESP AI model accelerates the identification of tight-binding antibodies, Nature Communications (2023). DOI: 10.1038/s41467-023-36028-8
Provided by
University of California – San Diego
Citation:
Artificial intelligence aids discovery of super tight-binding antibodies (2023, January 31)
retrieved 31 January 2023
from https://phys.org/news/2023-01-artificial-intelligence-aids-discovery-super.html
This document is subject to copyright. Apart from any fair dealing for the purpose of private study or research, no
part may be reproduced without the written permission. The content is provided for information purposes only.
Source: https://news.google.com/__i/rss/rd/articles/CBMiT2h0dHBzOi8vcGh5cy5vcmcvbmV3cy8yMDIzLTAxLWFydGlmaWNpYWwtaW50ZWxsaWdlbmNlLWFpZHMtZGlzY292ZXJ5LXN1cGVyLmh0bWzSAU5odHRwczovL3BoeXMub3JnL25ld3MvMjAyMy0wMS1hcnRpZmljaWFsLWludGVsbGlnZW5jZS1haWRzLWRpc2NvdmVyeS1zdXBlci5hbXA?oc=5